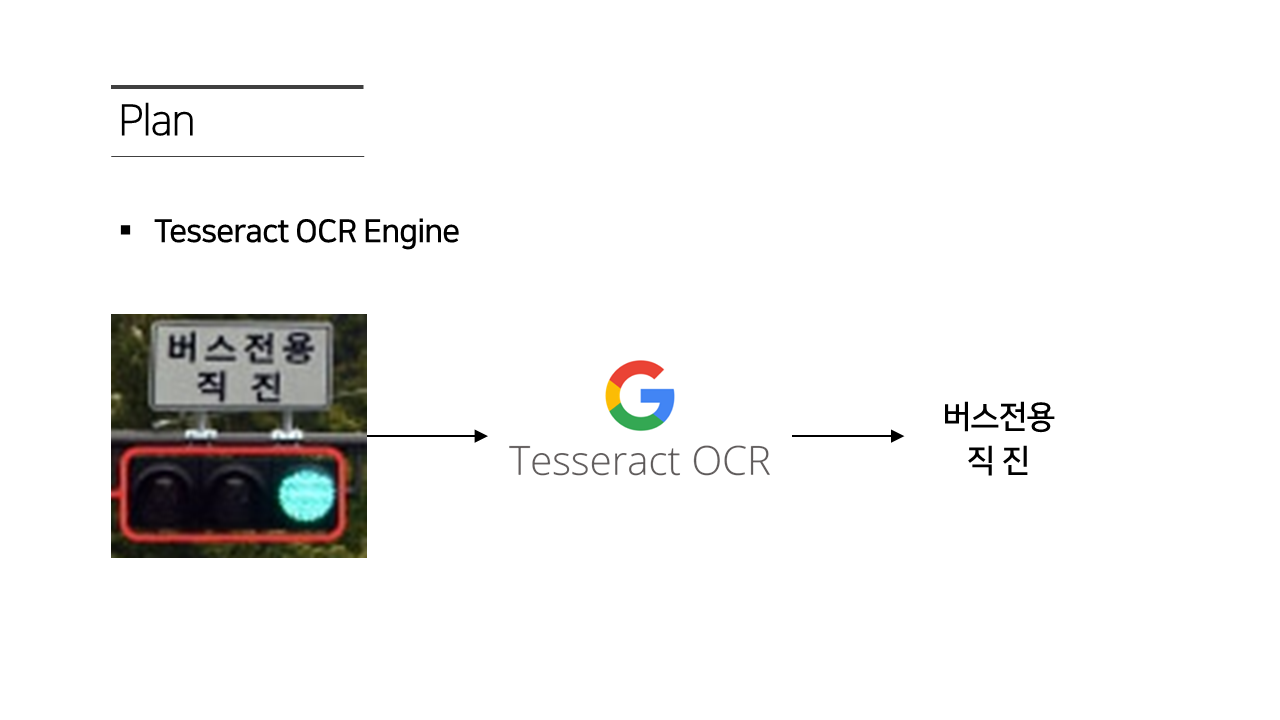
YOLO Usage on Windows
- 컴파일, Linux에서의 사용법은 다루지 않았습니다.
- AlexeyAB의 darknet을 참고하여 작성했습니다.
- 순서를 실제로 사용하면서 보게 되는 순서대로 바꿨습니다.
- 최근 수정 : 2019년 4월 2일
Pre-trained models Download
- https://github.com/AlexeyAB/darknet#pre-trained-models
- 다운 받은 뒤
darknet.exe와 같은 디렉토리에 저장한다.
How to Train
- 쓰려고 하는 cfg 파일을 수정한다.
batch=64subdivision=8height와width는 32의 배수로 크면 클수록 정확도가 높다.classes=을 검색해서 자신의 class 갯수로 수정한다.classes=을 검색했을 때, 위에 나오는filters=역시 수정해야하는데, 그 값은(classes+5)*3이다.- 다른 해상도에 대한 정확도를 높이려면 파일의 맨아래
random=1로 수정한다. - Small Object(
416*416으로 Resizing 했을때16*16보다 작은 경우)라면 Line #720에layers = -1, 11, Line #717에stride=4로 수정한다. anchors=를 수정한다.- anchors 계산 :
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416
- anchors 계산 :
- 좌우 구별 감지를 원하면 Line #17
flip=0을 입력한다.
-
data 파일을 만들어야 한다.
classes = 3 train = EXAMPLE1/train.txt valid = EXAMPLE1/test.txt names = EXAMPLE1/obj.names backup = EXAMPLE1/backup/ # 중간 weights를 저장하는 경로 -
names 파일을 만들어야한다.
- class 0, 1, 2 ... 이름을 적는다
bird dog cat
- class 0, 1, 2 ... 이름을 적는다
-
Training 및 Testing 시에 쓸 이미지 파일을
build\darknet\x64\EXAMPLE1에 저장한다.- 물론 이 이미지들은 Bounding Box처리가 되어 있어야한다.
- 다음 링크에서 marking을 하는 툴을 받을 수 있다. Box 작업에는 큰 인내와 끈기가 필요하다.
-
이미지 리스트의 상대 경로가 적혀있는 txt 파일을 생성해야한다.
-
이미지가 3개이고 경로가
darknet.exe가 있는 디렉토리에 있는EXAMPLE1에 있는 경우train.txt가 아래와 같은 내용이여야한다.EXAMPLE/img1.jpg EXAMPLE/img2.jpg EXAMPLE/img3.jpg
-
-
darknet.exe detector train .data .cfg .weights로 Training 시킬 수 있다.- Training 시에 Loss-Window를 띄우지 않으려면
-dont_show옵션을 설정하면 된다.
- Training 시에 Loss-Window를 띄우지 않으려면
-
Training 후에는 아래 명령어로 어느 weights가 어느 정도의 성능을 보이는지 확인할 수 있다.
darknet.exe detector map .data .cfg .weights -
mAP-chart
darknet.exe detector train .data .cfg .weights -map
Usage (After Training)
- https://github.com/AlexeyAB/darknet#how-to-use-on-the-command-line
- cfg 파일에서
height와width를 늘린다.(608 or 832: 32의 배수로)Out of memory오류가 난다면subdivision을 16, 32, 64 등으로 증가시킨다.
- Image :
darknet.exe detector test .data .cfg .weights -thresh THRESH OPTION- OPTION
- Output coordinates :
-ext_output - Use GPU 1 :
-i 1 - List of Image에 대한 결과 저장 :
-thresh 0.25 -dont_show -save_labels < list.txt
- Output coordinates :
- OPTION
- Video :
darknet.exe detector demo .data .cfg .weights .videofile OPTION- OPTION
- WebCam 0 :
-c 0 - Net-videocam :
http://192.168.0.80:8080/video?dummy=param.mjpg - Save result :
-out_filename OUT.videofile
- WebCam 0 :
- OPTION
- Check accuracy mAP@IoU=75 :
darknet.exe detector map .data .cfg .weights -iou_thresh 0.75
Using Android smartphone(Network Video-Camera)
- 어플 다운로드
- WiFi 혹은 USB로 컴퓨터와 스마트폰 연결
- 어플 실행
darknet.exe detector demo .data .cfg .weights http://192.168.0.80:8080/video?dummy=param.mjpg -i 0으로 실행
YOLO in other frameworks
'머신러닝 > YOLO' 카테고리의 다른 글
| [YOLO] YOLO Build on Windows, VS 2017 (0) | 2019.01.06 |
|---|---|
| [YOLO] Yolo_mark로 bounding box 그리기 on Windows (2) | 2018.12.28 |
| [Darkflow] Darkflow 설치 및 사용법 on Windows (0) | 2018.11.21 |
| Convert from Darknet annotations to Darkflow annotations(txt to xml) (7) | 2018.11.19 |
| [YOLO] YOLO(You Only Look Once) Training 및 Test 하는 법 (이미지 및 동영상) on Windows (4) | 2018.10.30 |